Understanding the Kafka transaction Layer With a practical code example
Understanding the Kafka transaction Layer
With a practical code example

In the fast-paced world of distributed computing and real-time data processing, Kafka, the messaging and event streaming system developed by Confluent, has become a cornerstone for a wide range of business applications. Kafka’s ability to handle massive streams of data and events has revolutionized how organizations tackle challenges related to data ingestion, processing, and distribution in highly scalable environments.
However, as enterprise applications and systems grow in complexity, the need to ensure data integrity and consistency within Kafka arises, especially in critical scenarios such as the financial sector, inventory management, and other processes where data consistency is paramount.
Kafka’s Transaction Layer is a crucial feature of Kafka Confluent and becomes an essential element to comprehend. In this article, we will delve deep into Kafka’s Transaction Layer, its significance in enterprise applications, how it works, and how to use it to ensure data consistency in high-velocity, high-availability environments. From its fundamental concepts to practical use cases, this guide will provide you with a solid foundation to understand and make the most of Kafka’s Transaction Layer.
What is Kafka?

Apache Kafka is an open-source messaging and event streaming system designed for real-time data ingestion, storage, processing, and distribution at a large scale. Kafka has become an essential technology in the field of data architecture and event processing, and it is used in a wide range of business applications.
At its core, Kafka functions as a highly distributed, fault-tolerant queuing system that enables applications to send and receive continuous streams of data and events. Events are published to topics and stored in Kafka server clusters, facilitating efficient processing and distribution.
Kafka is known for its ability to handle massive volumes of real-time data, high scalability, fault tolerance, and flexibility. It is used in various use cases, from log management to building complex event processing systems and real-time streaming applications. Kafka has proven to be particularly valuable in environments where speed, reliability, and scalability are critical.
Introduction to Kafka transaction layer
The Kafka Transaction Layer is a key feature of this system that provides the ability to ensure data integrity and consistency in critical enterprise environments. It allows users to group operations into transactions to ensure that events are published or not published coherently, which is essential in applications where data accuracy and reliability are paramount.
The Kafka Transaction Layer functions as an essential component to manage data integrity and consistency in high-performance enterprise settings. In a world where data accuracy and reliability are imperative, this feature enables organizations to orchestrate complex operations in a distributed environment with the confidence that events will be handled consistently and securely.
This functionality allows users to group multiple related operations into a single transaction, meaning that they all either run or do not run, ensuring that data is not left in an inconsistent state. The Kafka Transaction Layer acts as a vital safeguard in critical applications such as financial systems, where any error in data management could have significant consequences.
In this article, we will explore in detail how the Kafka Transaction Layer works, its benefits, and real-world use cases, to understand its crucial role in ensuring data integrity in high-stakes enterprise applications.
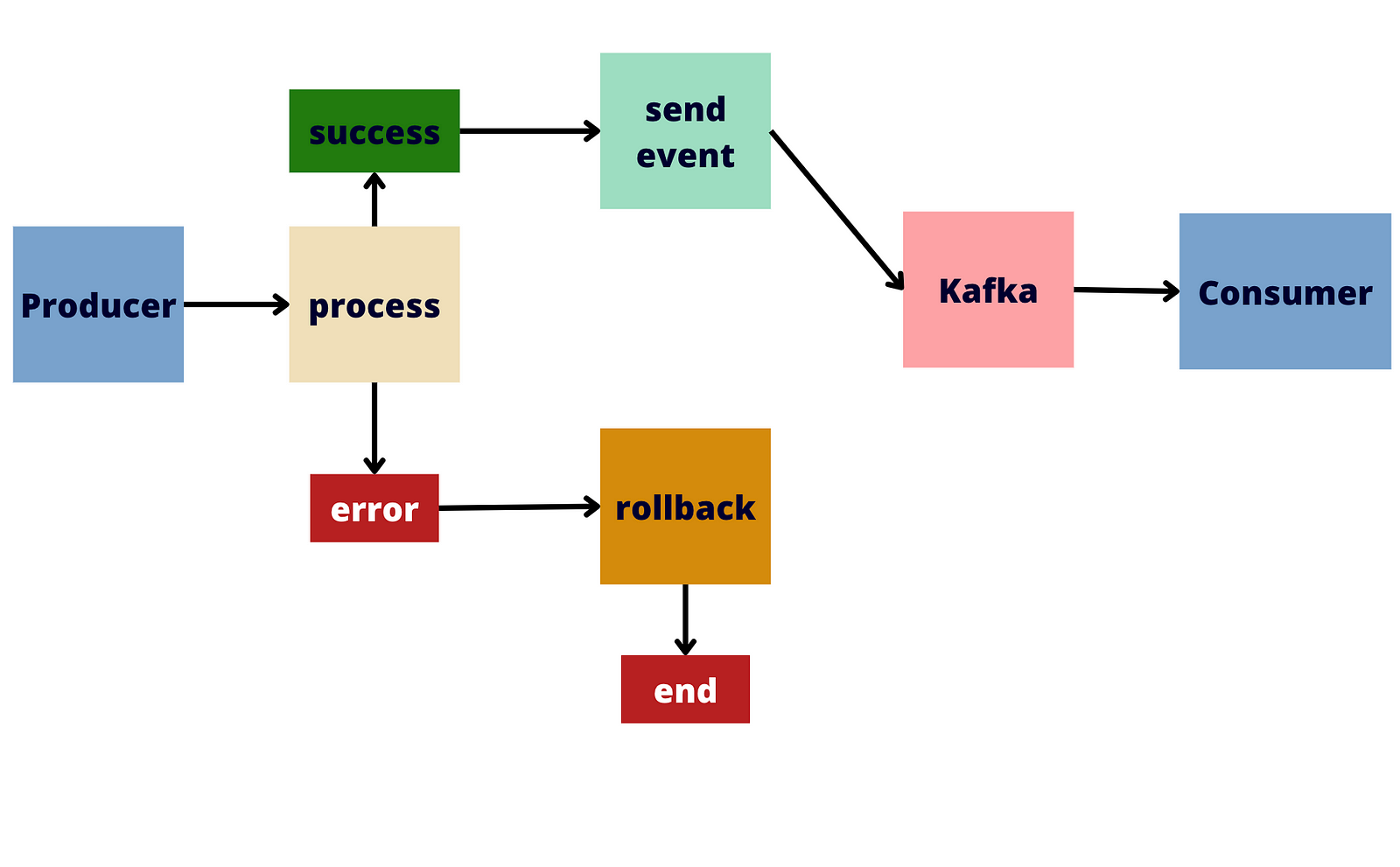
What is the Kafka transaction layer?
The Kafka Transaction Layer is a key feature that was introduced in Apache Kafka starting from version 0.11.0. This feature allows users to perform publish and consume operations in Kafka atomically, which means they either run completely and consistently or do not run at all. This ensures data integrity and consistency in critical situations, such as financial applications and other scenarios where accuracy and reliability are essential.
Interaction between Consumer, Producer, topic, and Partition
Kafka’s Transaction Layer integrates with the producer to enable atomic operations within specific topics and partitions. This ensures that messages are published consistently and securely in an enterprise environment where data integrity is critical. Consumers, while not directly involved in transactions, read messages from topics and partitions, emphasizing the importance of consistency and atomicity in Kafka.
The relationship between Kafka’s Transaction Layer, producer, consumer, topic, and partition is essential to understanding how transactions work in Kafka, in following provides a little description of how those components interact.
Producer
The producer is an essential part of implementing transactions in Kafka. It is responsible for sending messages to Kafka topics. When using the Transaction Layer, the producer groups message production operations into transactions to ensure their atomicity.
Consumer
Consumers in Kafka are responsible for reading and processing messages from topics. While the Transaction Layer is primarily associated with the producer, consumers can be indirectly involved in the transaction confirmation process.
Topic
A topic in Kafka is a category or channel of messages. Producers send messages to a topic, and consumers read from that topic. The Transaction Layer allows grouping message production operations within a specific topic into a transaction.
Partition
Kafka topics are divided into partitions, which are units of scalability and parallelism. Each partition can be thought of as an ordered sequence of messages. The Transaction Layer allows producers to group message production operations within a specific partition into a transaction.
Considerations when working with the Kafka Transaction Layer
Working with the Kafka Transaction Layer requires careful planning and attention to detail. This feature provides a critical level of consistency and atomicity in enterprise applications but must be used with knowledge and caution. Understanding the implications and proper planning are crucial to making the most of this feature.
In next are listed a couple of pints that helps us to know when could be a good opportunity to implement the “transaction layer”.
Proper Configuration:
Ensure that you configure the Transaction Layer correctly in your Kafka producer. This includes defining a unique transactional ID, enabling the enable.idempotence setting, and adjusting other transaction-related parameters.
Understand Requirements:
Before using transactions, understand your application’s requirements. Is it essential that operations are atomic and consistent? What happens if a transaction fails? This will help you determine if transactions are necessary.
Error Handling:
Be prepared to handle errors effectively. If an error occurs during a transaction, you must decide whether to commit or abort the transaction. Consider the consequences of both decisions.
Transaction Size:
Keep the size of transactions in mind. If transactions are too large, they could impact performance. Divide transactions into reasonable batches to balance performance and atomicity.
Latency:
Transactions can introduce latency into your operations. Consider the added latency from committing a transaction when designing your application.
Monitoring:
Implement a robust monitoring strategy to track the status of transactions. Kafka provides metrics and tools to monitor transaction progress and detect issues.
Retries and Retransmissions:
You should manage retries and retransmissions of transactions in case of failures. Use automatic retry mechanisms and recovery strategies to ensure transactions are completed.
State Backup:
Kafka’s Transaction Layer allows you to back up the state of a transaction in case of a failure. This helps you recover from potential errors and maintain data consistency.
Timeouts:
Adjust transaction timeouts according to your application’s needs. This may include timeouts for transaction commit and abort operations.
Documentation and Testing:
Document your transaction processes and conduct thorough testing. Ensure that the entire team understands how transactions work and how to handle errors.
Resilience:
Plan for resilience in case of catastrophic failures. Make sure your data can be restored, and your applications can recover from aborted or failed transactions.
Optimization:
Fine-tune your configuration and processes to optimize transaction performance and efficiency.
Understanding the Transaction Layer workflow
At this point is important to mention how the “Transaction Layer” works, and what do we need to implement in order to set a correct flow and integrate this awesome functionality in our distributed system workflows.
The following points are an explanation of how Kafka’s Transaction Layer works and what components or configurations form part of each one.
1) Initiating a Transaction
The process begins by initiating a transaction using the Kafka producer. This is done by calling producer.InitTransactions(), which puts the producer in a transactional state.
During the transaction initiation phase, a unique identifier is assigned to the transaction, which is used to track it.
2) Atomic Operations
Once a transaction is initiated, all message publishing and consuming operations that occur subsequently are considered part of that transaction.
All operations within the transaction, such as message publishing, message consumption, and acknowledgments, must succeed for the transaction to be subsequently confirmed. If any of these operations fail, the transaction is automatically aborted.
3) Atomic Publishing
When messages are sent to a specific topic within a transaction, those messages are batched together.
These batches of messages are not sent to Kafka until the transaction is confirmed. This ensures that the messages are not visible to consumers until it is guaranteed that the transaction will be successfully completed.
4) Confirmation or Abortion
At the end of the transaction, the producer can choose to confirm the transaction by calling producer.CommitTransaction() or abort it using producer.AbortTransaction(). Those options depend on the logic that we are implementing and if an error was propagated as part of a parallel process.
If the transaction is confirmed, all messages published within the transaction become visible to consumers and are considered permanent. Regularly we going to commit the transaction if the process was completed successfully.
If the transaction is aborted, all messages published within the transaction are discarded and not sent to Kafka. Regularly we going to abort the transaction if an error happens in the process, that going to help us to ensure the data integrity.
5) Transaction Control
Kafka provides tools for managing and monitoring transactions, such as tracking ongoing transactions and the ability to restore the transaction’s state in case of failure.
The complete flow could be visualized in the following pseudo-code example:
producer.inittransaction()
producer.publishTransactionMsg()
err = executeOtherProcessBetween()
if err is not null then:
producer.AbortTransaction()
return error
producer.CommitTransaction()Note: In the next section we going to practice this concepts in a code example
Differences between the Kafka transactions and the database transactions
Transactions in Kafka and transactions in a database share the fundamental concept of atomicity, consistency, isolation, and durability (ACID), but they differ in their implementation and purpose due to differences in the nature of operations and application requirements.
Those differences highlight the adaptation of the fundamental principles of atomicity, consistency, isolation, and durability (ACID) to specific contexts and needs. These differences underscore the versatility of these concepts in the world of computing and the importance of understanding how to apply them appropriately in different scenarios.
While both transactions in Kafka and transactions in databases share fundamental ACID principles, they are designed for different environments and applications. Transactions in Kafka focus on ensuring consistency and atomicity in real-time event streaming, while transactions in databases focus on ensuring data integrity in stored records and tables.
In Kafka, transactions are inherently linked to real-time event streaming, demanding that operations be atomic and consistent to ensure data integrity. This emphasis on real-time events and the ability to group operations into transactions is vital in event-processing applications and messaging systems.
On the other hand, in a database, transactions are meant to maintain the integrity of data stored in records and tables, and they have a more static focus compared to the dynamic nature of real-time events. Operations in databases often involve multiple tables and records, and transactions ensure data consistency in a more structured context.
Here are some key differences between transactions in Kafka and transactions in a database:
Purpose
- Kafka: Transactions in Kafka are used in scenarios where data integrity and consistency of real-time events are critical, such as event streaming applications, real-time processing applications, and messaging systems.
- Database: Transactions in databases are used to ensure data integrity in database management applications, such as enterprise applications, logging systems, and inventory management applications.
Data Type
- Kafka: Transactions in Kafka apply to message production and consumption operations. Kafka is used for real-time event and data streaming. Transactions in Kafka ensure that messages are published or not published consistently.
- Database: Transactions in a database apply to read and write operations on database records and tables. Database transactions ensure data consistency within records and tables.
Scope
- Kafka: Transactions in Kafka apply to producer and consumer operations within a messaging system. They ensure messages are published to topics atomically and consistently.
- Database: Transactions in a database apply to a specific set of operations that affect rows or records within a table. They ensure data consistency within a database transaction.
Scalability
- Kafka: Kafka is designed to be highly scalable and distributed. Transactions in Kafka can involve multiple producers and consumers in a distributed cluster.
- Database: Database transactions can also involve multiple operations on distributed databases, but the scalability and distribution of databases may differ from Kafka.
Durability
- Kafka: Kafka is designed to be highly durable and retains messages for a configurable period. Transactions in Kafka ensure published messages are persistent.
- Database: Databases are typically highly durable and ensure data written is persisted to storage.
Data Return
- Kafka: Transactions in Kafka typically do not provide a direct response or data return to the producer, as the primary focus is on real-time event publication and consumption.
- Database: Database transactions often provide information about the transaction’s status and may include confirmations or rollbacks.
The adaptability of ACID principles is what allows them to remain relevant in different domains. Transactions are a fundamental pillar of computing, and their careful and precise application can make a difference in data integrity and operation reliability. Understanding the contextual differences between transactions in Kafka and transactions in databases is essential for making informed decisions and designing systems that meet the specific needs of the applications in which they are used. Computing, ultimately, is a field of adaptation and flexibility, and transactions are a manifestation of how fundamental principles can be tailored to address diverse challenges.
Code example (Implemented with Golang)
In this section, we going to build one code example using the “Transaction Layers”. For this time we going to use Golang programming language.
To configure your confluent Kafka cluster you can review the following tutorial:
package main
import (
"context"
"fmt"
"log"
"time"
"github.com/confluentinc/confluent-kafka-go/kafka"
)
var (
broker = "<YOUR_BROKER_URL>"
topic = "example_1"
)
const (
CLUSTER_API_KEY = "<YOUR_CLUSTER_API_KEY>"
CLUSTER_API_SECRET = "<YOUR_CLUSTER_API_SECRET>"
)
func producer(transactionID int) {
log.Println("starting producer")
tID := fmt.Sprintf("test-transaction-%d", transactionID)
configMap := &kafka.ConfigMap{
"bootstrap.servers": broker,
"security.protocol": "SASL_SSL",
"sasl.mechanisms": "PLAIN",
"sasl.username": CLUSTER_API_KEY,
"sasl.password": CLUSTER_API_SECRET,
"acks": "all",
"enable.idempotence": "true",
"transactional.id": tID,
}
producer, err := kafka.NewProducer(configMap)
if err != nil {
log.Fatalf("Error al crear el productor de Kafka: %v", err)
return
}
defer producer.Close()
message := &kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Key: []byte("key-" + tID),
Value: []byte(tID),
}
if err := producer.InitTransactions(context.Background()); err != nil {
log.Fatalf("Error on init transaction: %v", err)
return
}
if err := producer.BeginTransaction(); err != nil {
log.Fatalf("Error on init transaction: %v", err)
return
}
err = producer.Produce(message, nil)
if err != nil {
log.Fatalf("Error produccing messagen: %v", err)
}
// fake transaction aborting process
if transactionID%2 == 0 {
log.Println("Abborting transaction -> ", transactionID)
producer.AbortTransaction(context.Background())
return
}
if err := producer.CommitTransaction(context.Background()); err != nil {
log.Fatalf("Error commiting transaction: %v", err)
}
}
func consumer() {
log.Println("starting consumer")
configMap := &kafka.ConfigMap{
"bootstrap.servers": broker,
"group.id": "mi-grupo",
"auto.offset.reset": "earliest",
"security.protocol": "SASL_SSL",
"sasl.mechanisms": "PLAIN",
"sasl.username": CLUSTER_API_KEY,
"sasl.password": CLUSTER_API_SECRET,
}
consumer, err := kafka.NewConsumer(configMap)
if err != nil {
log.Fatalf("Error creating kafka consumer: %v", err)
return
}
defer consumer.Close()
err = consumer.SubscribeTopics([]string{topic}, nil)
if err != nil {
log.Fatalf("Error subscribing to topic: %v", err)
return
}
for {
msg, err := consumer.ReadMessage(-1)
if err != nil {
log.Printf("error reading message: %v\n", err)
break
}
log.Printf("Reading message value: %s\n", string(msg.Value))
}
}
func main() {
fmt.Println("kafka transaction Layer")
go consumer()
count := 1
for {
time.Sleep(1 * time.Second)
producer(count)
count++
}
}Explaining the code:
In summary, the producer function is responsible for producing messages in Kafka transactions, allowing for the confirmation or abortion of transactions based on program logic. On the other hand, the consumer function is responsible for consuming messages from the subscribed topic and processing them in a continuous loop. Both functions are essential for demonstrating how transactions work in Kafka and how the produced messages can be consumed.
producer Function:
- A Kafka producer is created using the Confluent Kafka Go library. Important parameters are configured, such as the broker address, SASL authentication credentials, the acks level, enabling idempotence, and transaction identification.
- The producer’s transaction is initialized using
producer.InitTransactions(context.Background()). This prepares the producer to begin a transaction. - A new transaction is started with
producer.BeginTransaction(). From this point onward, all message production operations will be part of this transaction. - A Kafka message is created, including the target topic for the message, a key, and a value.
- The message is produced using
producer.Produce(message, nil). The message is sent to the specified topic as part of the transaction. - A transaction abort logic is simulated based on the value of
transactionID. IftransactionIDis even, the transaction is aborted usingproducer.AbortTransaction(context.Background()). This means that the messages produced in this transaction will not be confirmed and will be discarded. - If the abort logic is not triggered, the transaction is committed using
producer.CommitTransaction(context.Background()). This ensures that the messages produced in the transaction are confirmed and visible to consumers.
consumer Function:
- A Kafka consumer is created using the Confluent Kafka Go library. Parameters like the broker address, consumer group, offset start configuration, and SASL authentication credentials are set.
- It subscribes to the
topicusingconsumer.SubscribeTopics([]string{topic}, nil). This allows the consumer to receive messages from that topic. - The consumer enters an infinite loop where it waits for and processes incoming messages. When a message arrives, it is read and logged.
Conclusion
Throughout this article, we have explored the use of the Kafka Transaction Layer, a fundamental feature that enables the management of atomic operations in the world of event processing and real-time messaging. We have examined its features, its implementation in Golang, and how it relates to the producer, consumer, topics, and partitions in Kafka. We have also compared Kafka transactions to transactions in databases, highlighting the fundamental differences in their applications and approaches.
In summary, Kafka transactions are a powerful tool that ensures consistency and atomicity in applications that rely on data integrity in real-time. Their use extends to a variety of scenarios, from messaging systems to real-time event processing applications. The ability to group operations into transactions provides a high degree of security in a world where data accuracy is essential.
The comparison with database transactions underscores the adaptability of fundamental ACID principles in different application domains. Each of these systems addresses specific challenges, and their proper understanding and use are crucial to ensure data integrity and operation reliability in their respective contexts.
Ultimately, this article illustrates the importance of flexibility and adaptability in computing, where the same fundamental principles can be effectively applied in a variety of environments to meet diverse needs. Informed decision-making and a deep understanding of the available tools are essential for designing systems that meet the specific requirements of the applications and environments in which they operate.