Understanding Kafka: A Hands-On Guide with Golang Examples
Understanding Kafka: A Hands-On Guide with Golang Examples
Understanding Confluent Kafka: A Comprehensive Introduction
In the world of distributed streaming data and event-driven architectures, Confluent Kafka has emerged as a powerful and widely adopted platform. It’s not just Kafka; it’s Kafka with enhancements and extensions provided by Confluent Inc. In this article, we’ll explore what Confluent Kafka is, its features, and how it has revolutionized how data is processed and managed in the modern software landscape.
What is Kafka?
Before delving into Confluent Kafka, it’s crucial to understand the foundation it builds upon: Apache Kafka. Kafka is an open-source distributed streaming platform initially developed by LinkedIn, and it is designed to handle real-time data feeds efficiently. Kafka is characterized by its high throughput, fault tolerance, scalability, and durability.
Kafka achieves this by providing a publish-subscribe messaging system where data producers (publishers) can send records to topics, and data consumers (subscribers) can consume records from these topics. Topics act as channels for organizing data streams, and Kafka uses a distributed, fault-tolerant architecture to store and replicate data across multiple servers.
Key Points About Kafka: A High-Performance Data Streaming Platform
Kafka is a widely used high-performance data streaming platform in the industry. Here are some key points that highlight its features and advantages:
- High Performance: Kafka is known for its high performance and ability to handle millions of events per second, making it ideal for applications requiring real-time data streaming at a large scale.
- Durability: Kafka stores data durably and can be configured to retain data for a specific period. This ensures that data is not lost and remains available even after being consumed.
- Scalability: Kafka is highly scalable, allowing for easy addition of more servers and partitions to handle growing workloads. This makes it suitable for enterprises with scalability requirements.
- Fault Tolerance: Kafka is fault-tolerant and can recover from issues such as server crashes without data loss. This is essential in critical applications.
- Publish-Subscribe Model: Kafka uses the publish-subscribe model, enabling multiple producers to publish data to a topic and multiple consumers to subscribe to that topic.
- Partitioning: Topics in Kafka are divided into partitions, allowing for increased parallelism and scalability by distributing workloads.
- Configurable Data Retention: Kafka allows configuration of how long data is retained in a topic and how older data is discarded. This is useful for managing data storage and data flow.
- Stream Processing: Kafka Streams and KSQL are components that enable real-time data processing directly within the Kafka platform. This simplifies the development of real-time data processing applications.
- Abundant Ecosystem: Kafka has a rich ecosystem of connectors and tools that facilitate integration with various technologies, from databases to analytics systems.
- Configurable Data Retention: Kafka allows configuration of how long data is retained in a topic and how older data is discarded. This is useful for managing data storage and data flow.
- Security: Kafka offers security features such as authentication, authorization, and data encryption to protect data streams.
- Monitoring and Management: With tools like Confluent Control Center, it’s possible to effectively monitor and manage Kafka clusters.
- Community and Professional Support: Kafka has an active community, and companies like Confluent offer professional support for Kafka implementations.
- Versatile Use Cases: Kafka is used in a variety of use cases, including event logging, real-time processing, activity tracking, big data analytics, and more.
Kafka is a robust platform for real-time data streaming with a range of key features that make it suitable for a wide variety of applications in today’s industry. Its scalability, fault tolerance, and real-time processing capabilities are particularly notable.
Confluent Kafka: An Evolution
Confluent Kafka, often referred to as Confluent Platform is a distribution of Kafka that comes with additional features, tools, and extensions provided by Confluent Inc., a company co-founded by the creators of Kafka. Confluent has taken Kafka to the next level by enhancing its capabilities and making it more accessible to enterprises and organizations.
Key Features and Components of Confluent Kafka
Confluent Kafka offers a rich ecosystem of tools and components that extend the functionality of the core Kafka platform. Here are some key features and components of Confluent Kafka:
1. Confluent Platform:
The platform bundles Kafka with additional components like the Schema Registry, Connect, and Control Center to provide a more comprehensive event streaming platform.
2. Schema Registry:
This component allows for the management and evolution of data schemas, enabling compatibility between data producers and consumers.
3. Kafka Connect:
Kafka Connect is a framework for easily integrating Kafka with various data sources and sinks. It simplifies the process of getting data in and out of Kafka.
4. KSQL:
KSQL is a streaming SQL engine for Kafka. It enables real-time data processing with familiar SQL syntax, making it accessible to a broader range of users.
5. Control Center:
Control Center provides monitoring, management, and diagnostics for your Kafka clusters. It offers real-time insights into the performance and health of your Kafka infrastructure.
6. Enterprise Security:
Confluent Kafka offers robust security features, including encryption, authentication, authorization, and audit logs, to ensure your data remains secure.
7. Multi-Datacenter Replication:
Confluent provides tools for replicating data between Kafka clusters in different data centers, making it possible to build globally distributed event streaming pipelines.
8. Support and Professional Services:
Confluent Inc. offers support, training, and consulting services to help organizations deploy and manage Kafka effectively.
Use Cases for Confluent Kafka
Confluent Kafka has found applications in various domains, including:
- Real-Time Data Ingestion and Processing: Confluent Kafka is widely used for ingesting and processing real-time data streams, making it suitable for applications like IoT, fraud detection, and real-time analytics.
- Log Aggregation: Many organizations use Confluent Kafka to centralize and aggregate logs from various services, making it easier to monitor and troubleshoot their systems.
- Event Sourcing: Confluent Kafka is a preferred choice for implementing event-sourcing patterns in microservices architectures.
- Stream Processing: The Kafka Streams API and KSQL enable real-time stream processing, allowing businesses to react to events as they occur.
Understanding Producers, Consumers, and Message Anatomy
Kafka, a distributed streaming platform, has become a cornerstone of modern data architectures, facilitating real-time data streaming and event-driven applications. At the heart of Kafka lie producers and consumers, two key components that enable the seamless flow of data. In this article, we will explore the roles of producers and consumers in Kafka, the considerations for sending and consuming messages, and the anatomy of Kafka messages.
Kafka Producers: Initiating the Data Flow
Producers in Kafka are responsible for sending data, also known as messages, to Kafka topics. These messages can be generated by various applications, devices, or systems. Here are the essential aspects to consider when working with Kafka producers:
1. Data Serialization:
Messages sent by producers need to be serialized into bytes to be transmitted efficiently. Common serialization formats include Avro, JSON, or even plain text.
2. Message Key:
Producers can specify a key for each message. Keys are used to determine the partition to which a message will be sent. Careful selection of keys can improve data distribution and retrieval.
3. Topic Selection:
Producers choose the topic to which they send messages. Topics serve as categories for organizing related messages. Topics can be created dynamically or exist beforehand.
4. Acknowledgment:
Producers can configure the acknowledgment level for message delivery. Acknowledgments can be set to ensure a message is successfully written to Kafka before the producer proceeds.
5. Error Handling:
Producers should be equipped to handle errors, such as network issues or Kafka cluster unavailability. Retrying message transmission and logging errors are common practices.
Kafka Consumers: Receiving and Processing Data
Consumers in Kafka retrieve and process messages from Kafka topics. Here are the crucial considerations when dealing with Kafka consumers:
1. Grouping:
Consumers can be organized into consumer groups. Each group can have multiple consumers, and Kafka ensures that each message is delivered to only one consumer within a group. This allows for parallel message processing.
2. Offset Management:
Kafka consumers maintain an offset, which represents their position in a topic. Careful offset management ensures that consumers do not miss messages or process them more than once.
3. Data Deserialization:
Consumers must deserialize the bytes received from Kafka to access the original data. Deserialization is performed using the same serialization format used by producers.
4. Scalability:
Kafka consumers can be scaled horizontally to handle high message throughput. Load balancing and partition assignment are managed by Kafka.
5. Acknowledgment:
Consumers acknowledge the successful processing of messages. This is important for ensuring that messages are not processed more than once.
Anatomy of Kafka Messages
Kafka messages are the units of data exchange in the Kafka ecosystem. Each message consists of three primary parts:
1. Key:
The message key, often a string or binary value, is used for partitioning and routing messages to topics. It can also be used for indexing and quick retrieval of specific messages.
2. Value:
The message value contains the actual data to be transmitted. This can be any binary data, including structured data like JSON, Avro, or plain text.
3. Timestamp:
Kafka messages include a timestamp, representing the time the message was produced. This allows for time-based event processing and ordering of messages.
Kafka producers and consumers are fundamental components in the Kafka ecosystem, enabling the efficient and real-time flow of data. Understanding the considerations for producing and consuming messages, as well as the anatomy of Kafka messages, is essential for building robust and scalable data streaming applications. With the power of Kafka, organizations can effectively process and leverage real-time data for a wide range of use cases, from log aggregation to complex event processing.
Practical example
Configuring Cluster:
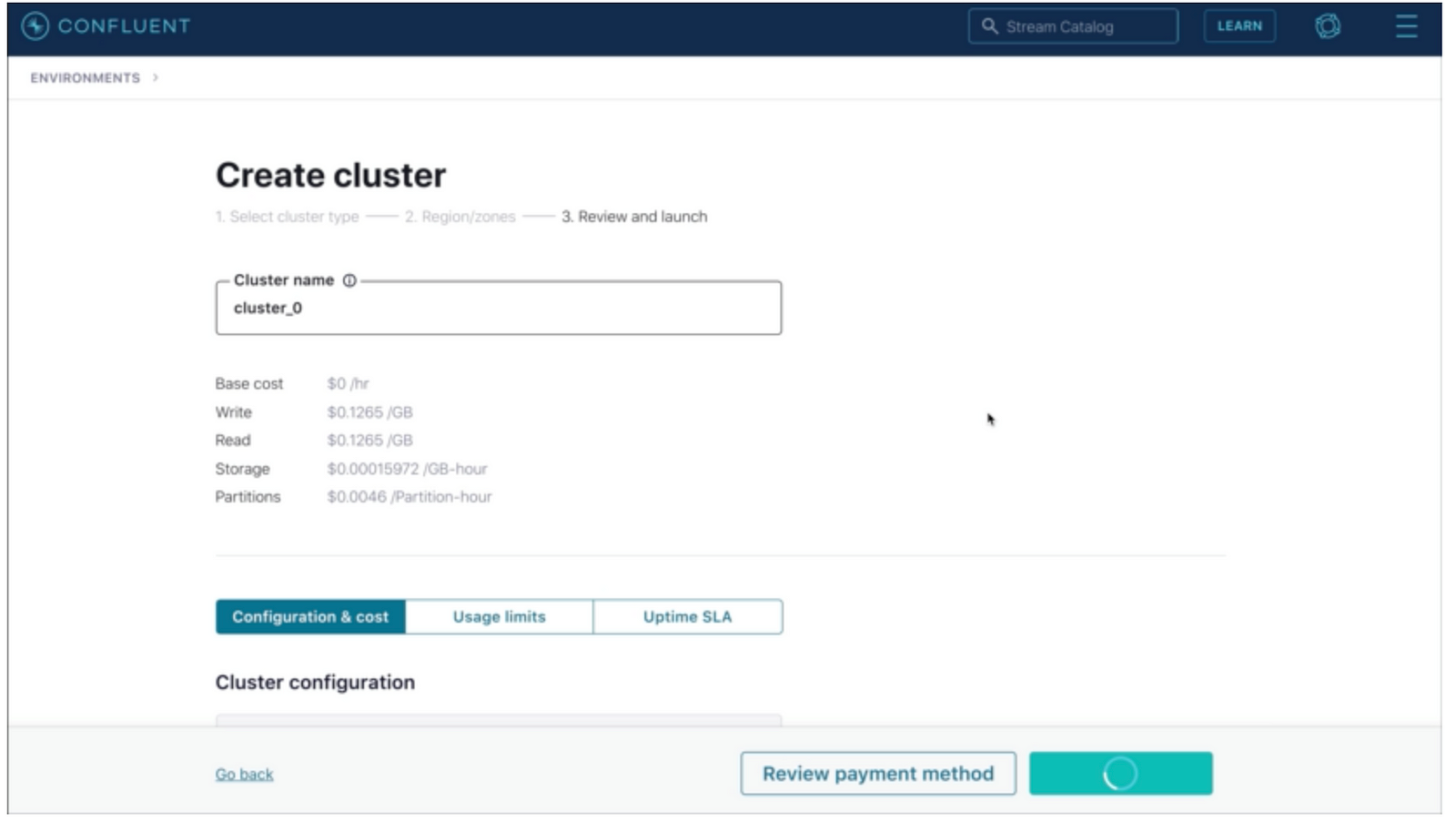
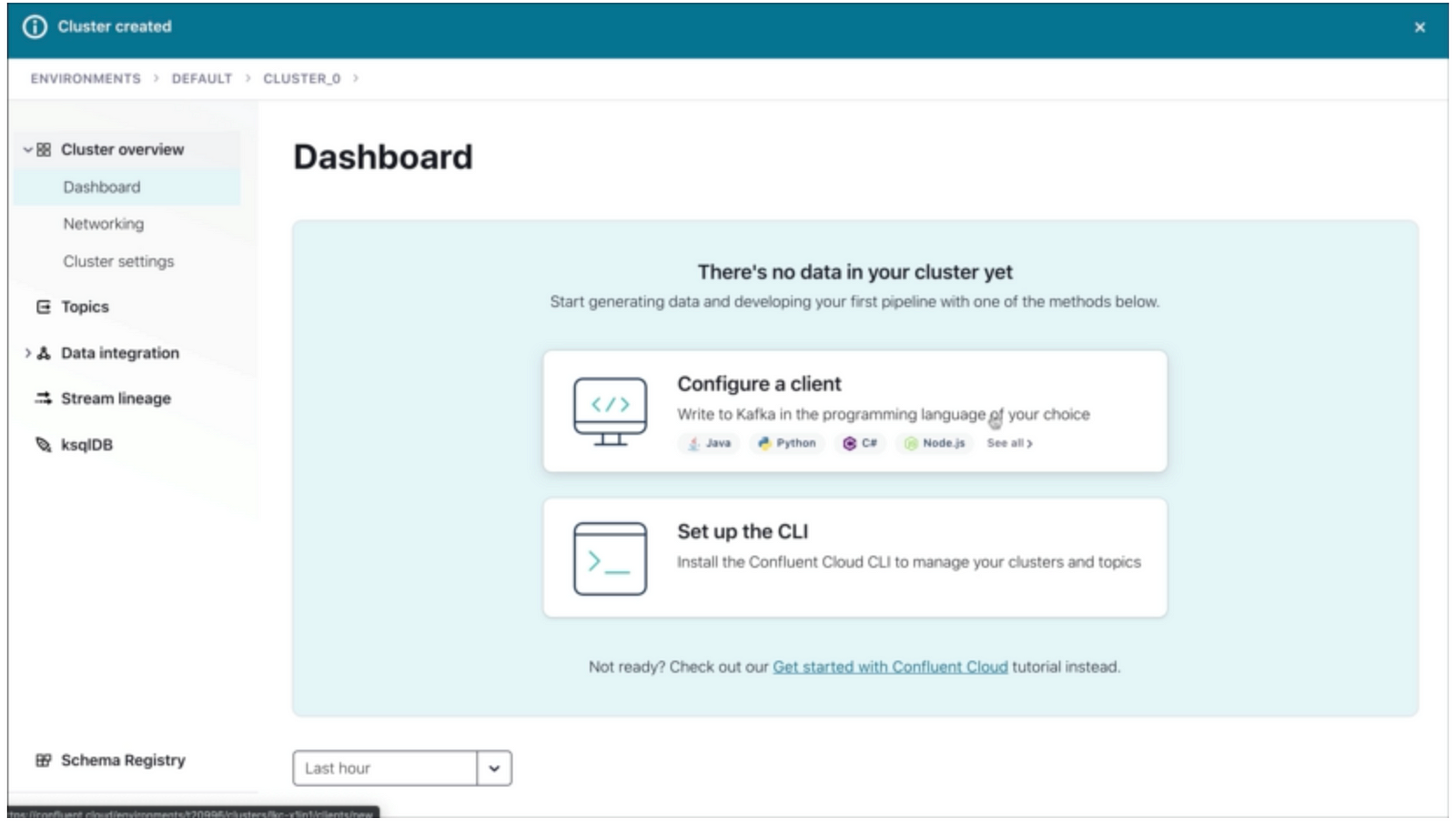
Select Basic
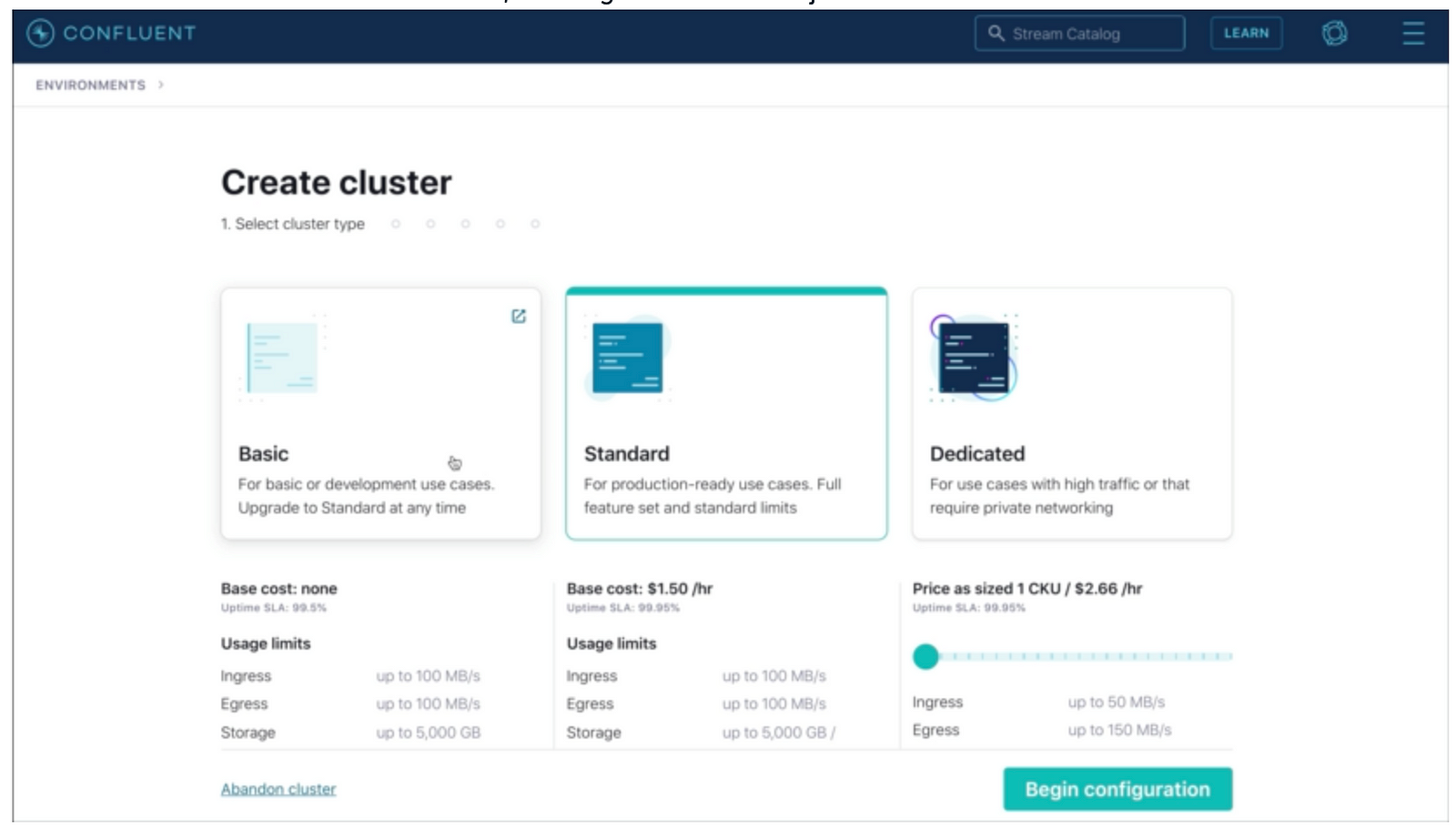
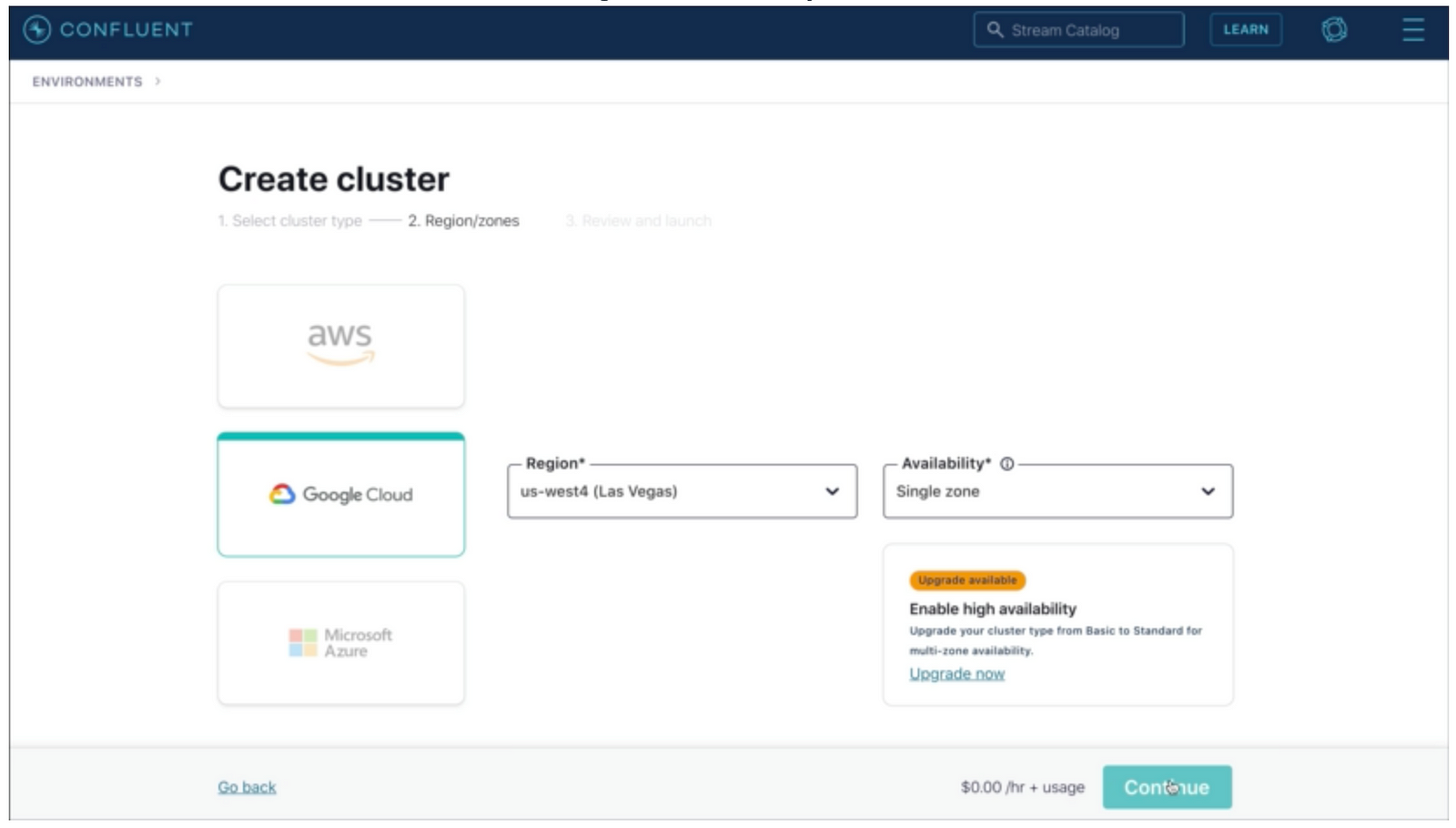
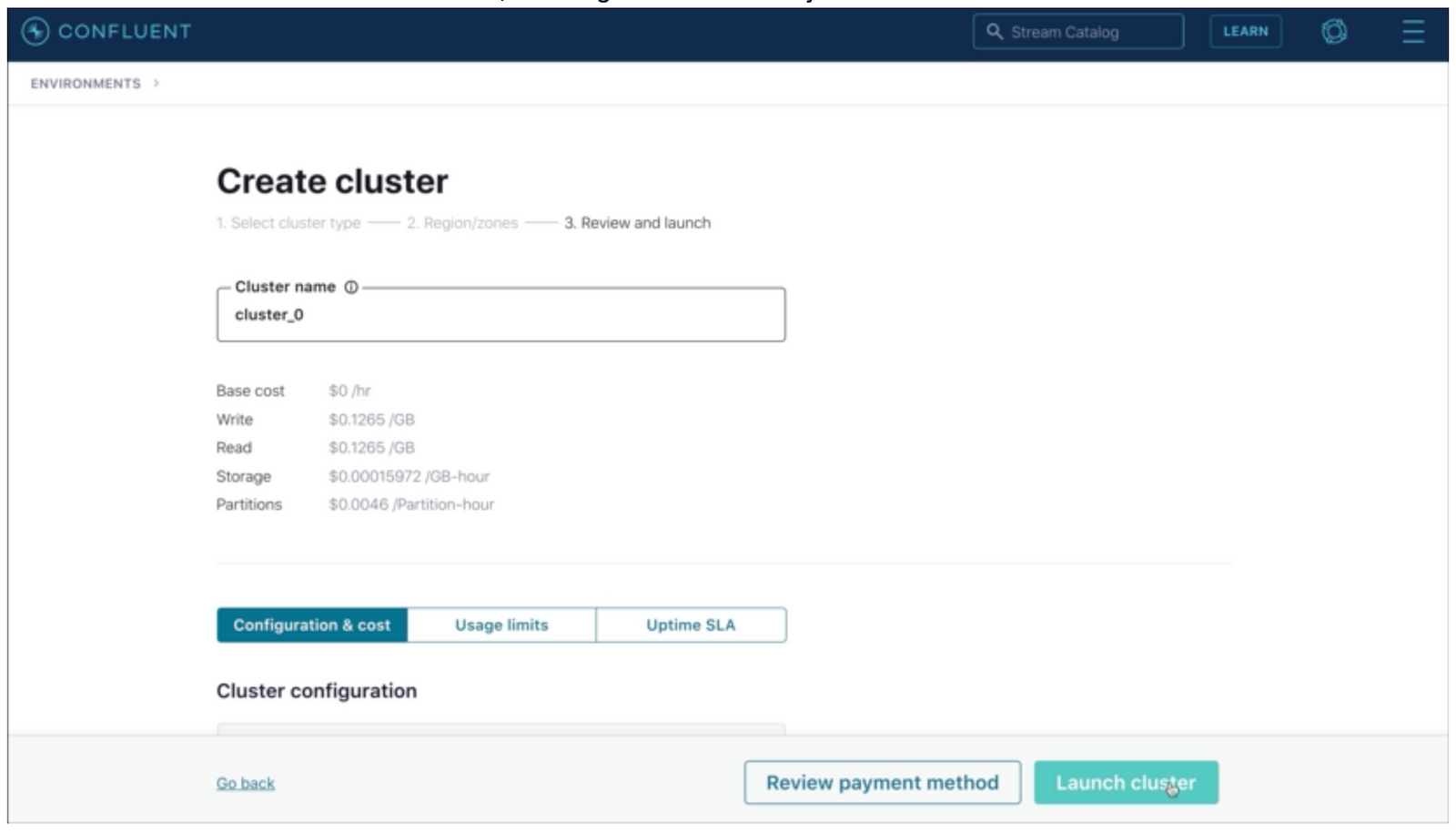
Create the Golang project
mkdir kafka-tutorial
cd kafka-tutorial
go mod init kafka-go-getting-started
go get github.com/confluentinc/confluent-kafka-go/kafkaAdding the code
In this example we going to build a very simple “Producer” and “Consumer”:
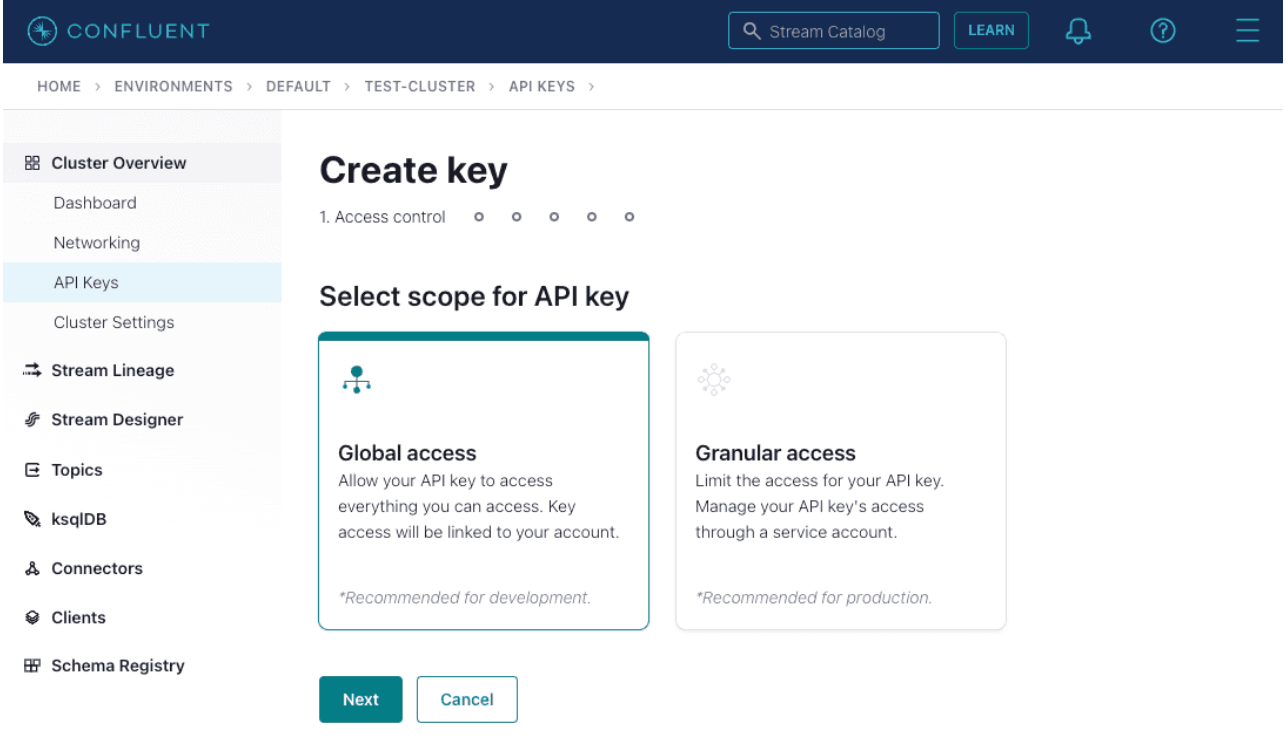
To get your API_KEY and API_SECRET you need to do the following steps:
Go to API Keys and generate a Global access one:
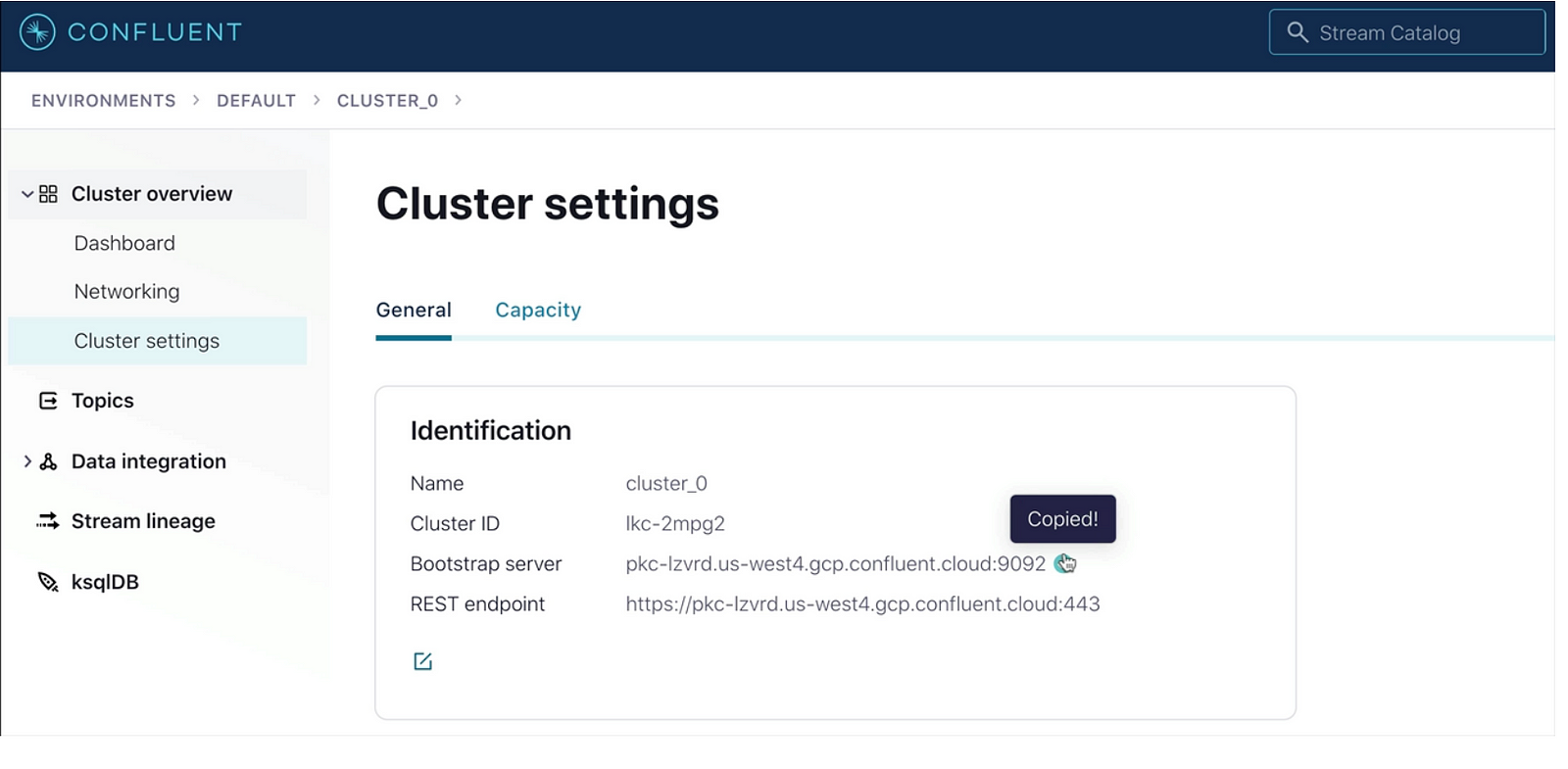
To get the cluster URL you need to go to cluster settings and copy the Bootstrap server URL:
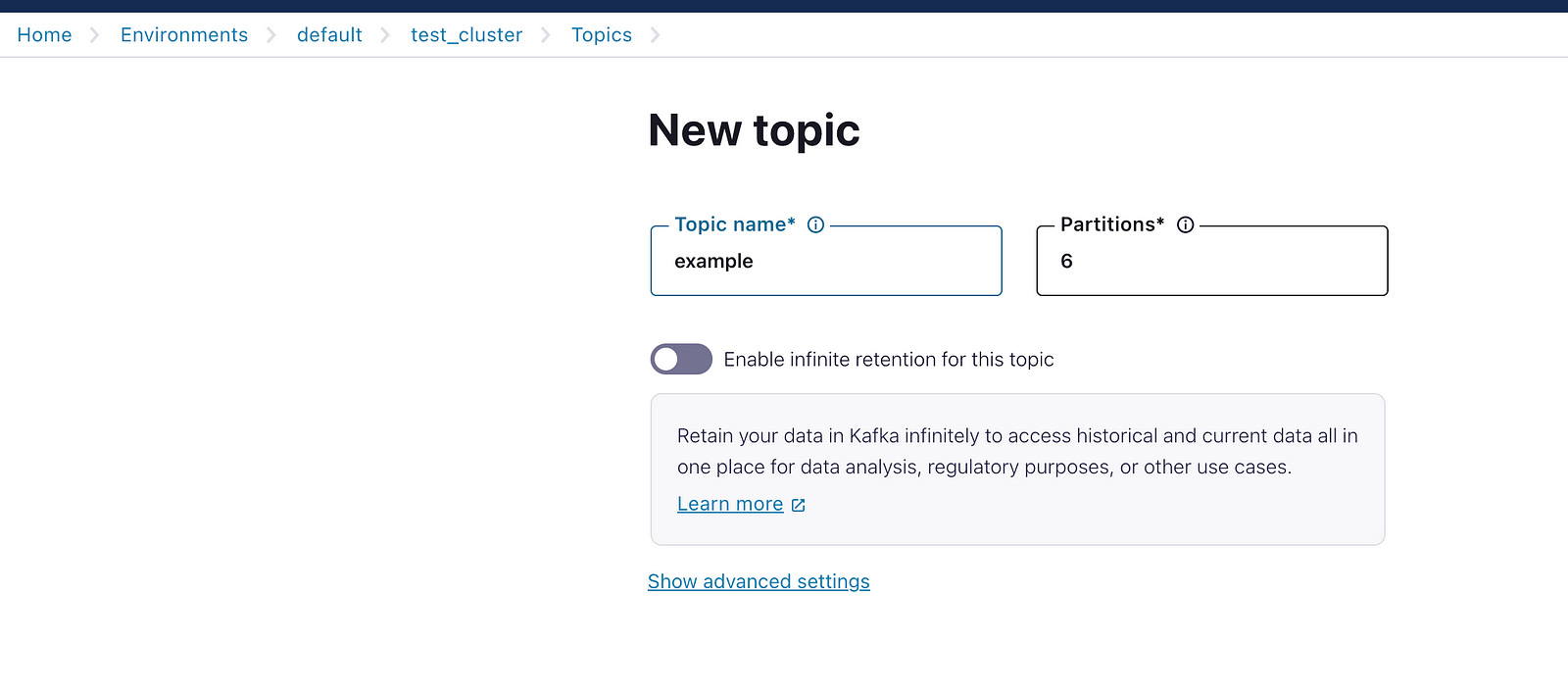
Create the Topic:
Now the code:
package main
import (
"fmt"
"os"
"os/signal"
"syscall"
"time"
"github.com/confluentinc/confluent-kafka-go/kafka"
)
var (
broker = "<URL>"
topic = "example"
)
const (
CLUSTER_API_KEY = "<API_KEY>"
CLUSTER_API_SECRET = "<API_SECRET>"
)
func startProducer() error {
//Producer configuration
producer, err := kafka.NewProducer(&kafka.ConfigMap{
"bootstrap.servers": broker,
"security.protocol": "SASL_SSL",
"sasl.mechanisms": "PLAIN",
"sasl.username": CLUSTER_API_KEY,
"sasl.password": CLUSTER_API_SECRET,
"acks": "all",
})
if err != nil {
fmt.Printf("Error creating the producer: %s\n", err)
return err
}
defer producer.Close()
// Produce messages
sigchan := make(chan os.Signal, 1)
signal.Notify(sigchan, os.Interrupt)
run := true
fmt.Printf("Producer ready. (Ctrl+C to end the process):\n")
count := 0
for run {
time.Sleep(1 * time.Second)
count++
select {
case sig := <-sigchan:
fmt.Printf("Caught signal %v: terminating...\n", sig)
run = false
default:
text := fmt.Sprintf("This is a simple text tes message. %d", count)
producer.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Value: []byte(text),
}, nil)
//producer.Flush(1000)
}
}
count = 0
return nil
}
func startConsumer() error {
consumer, err := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": broker,
"group.id": "mi-grupo",
"auto.offset.reset": "earliest",
"security.protocol": "SASL_SSL",
"sasl.mechanisms": "PLAIN",
"sasl.username": CLUSTER_API_KEY,
"sasl.password": CLUSTER_API_SECRET,
})
if err != nil {
fmt.Printf("Error creating Consumer: %s\n", err)
return err
}
defer consumer.Close()
// Suscribe to topic
err = consumer.SubscribeTopics([]string{topic}, nil)
if err != nil {
fmt.Printf("Error subscribing to topic: %s\n", err)
return err
}
// Set up a channel for handling Ctrl-C, etc
sigchan := make(chan os.Signal, 1)
signal.Notify(sigchan, syscall.SIGINT, syscall.SIGTERM)
// Process messages
run := true
for run {
select {
case sig := <-sigchan:
fmt.Printf("Caught signal %v: terminating\n", sig)
run = false
default:
ev, err := consumer.ReadMessage(100 * time.Millisecond)
if err != nil {
// Errors are informational and automatically handled by the consumer
continue
}
fmt.Printf("Consumed event from topic %s: key = %-10s value = %s\n",
*ev.TopicPartition.Topic, string(ev.Key), string(ev.Value))
}
}
return nil
}
func main() {
cnh := make(chan int)
go startProducer()
go startConsumer()
<-cnh
}Explaining the code:
In summary, this Go program configures a Kafka producer and consumer to interact with a Kafka cluster, demonstrating real-time message production and consumption. Both functions run in the background, and the main program waits for them to gracefully shut down in response to an interrupt signal. Here’s an explanation of the startProducer and startConsumer functions:
startProducer() Function
This function is responsible for setting up and running a message producer in a Kafka cluster. Here’s a detailed description of what it does:
1. Producer Configuration: A new Kafka producer is created and configured to communicate with a Kafka cluster. The configuration includes the bootstrap server address, security protocol (SASL_SSL), authentication mechanism, username, and password.
2. Production Loop: The function enters a loop that produces messages to the Kafka cluster. In each iteration of the loop, a message is created with a value containing simple text and an incremented sequence number. This message is sent to the specified topic. A signal (`sigchan`) is used to detect interrupt signals (such as Ctrl+C) and terminate the production loop.
3. Producer Closure: After the production loop ends (due to an interrupt signal), the producer is closed to release resources.
startConsumer() Function
This function sets up and runs a message consumer that receives messages from a Kafka cluster. Here’s a detailed explanation of how it works:
1. Consumer Configuration: A new Kafka consumer is created with a configuration similar to that of the producer. This includes the bootstrap server address, the consumer group to join, and configuration to read from the beginning of the topic (configured as “earliest”).
2. Topic Subscription: The consumer subscribes to a specific topic. In this case, it uses the same topic name as the producer.
3. Consumption Loop: The function enters a loop that reads messages from the Kafka cluster. It uses a signal channel (`sigchan`) to detect interrupt signals and terminate the consumption loop. In each iteration, it attempts to read a message from the Kafka cluster.
4. Message Processing: If a message is successfully received, the message information is printed, including the topic, key, and value of the message. Messages are processed in real-time.
5. Consumer Closure: When an interrupt signal is detected, the consumption loop ends, and the consumer is closed to release resources.
The main() Function
The `main` function is responsible for executing the `startProducer` and `startConsumer` functions in separate goroutines (concurrent threads). It then waits for a termination signal (control signal). This allows both functions to run simultaneously and gracefully stop when an interrupt signal is received. The main goroutine (`main`) blocks and waits until a signal (`<-cnh`) is received.
Running the code:
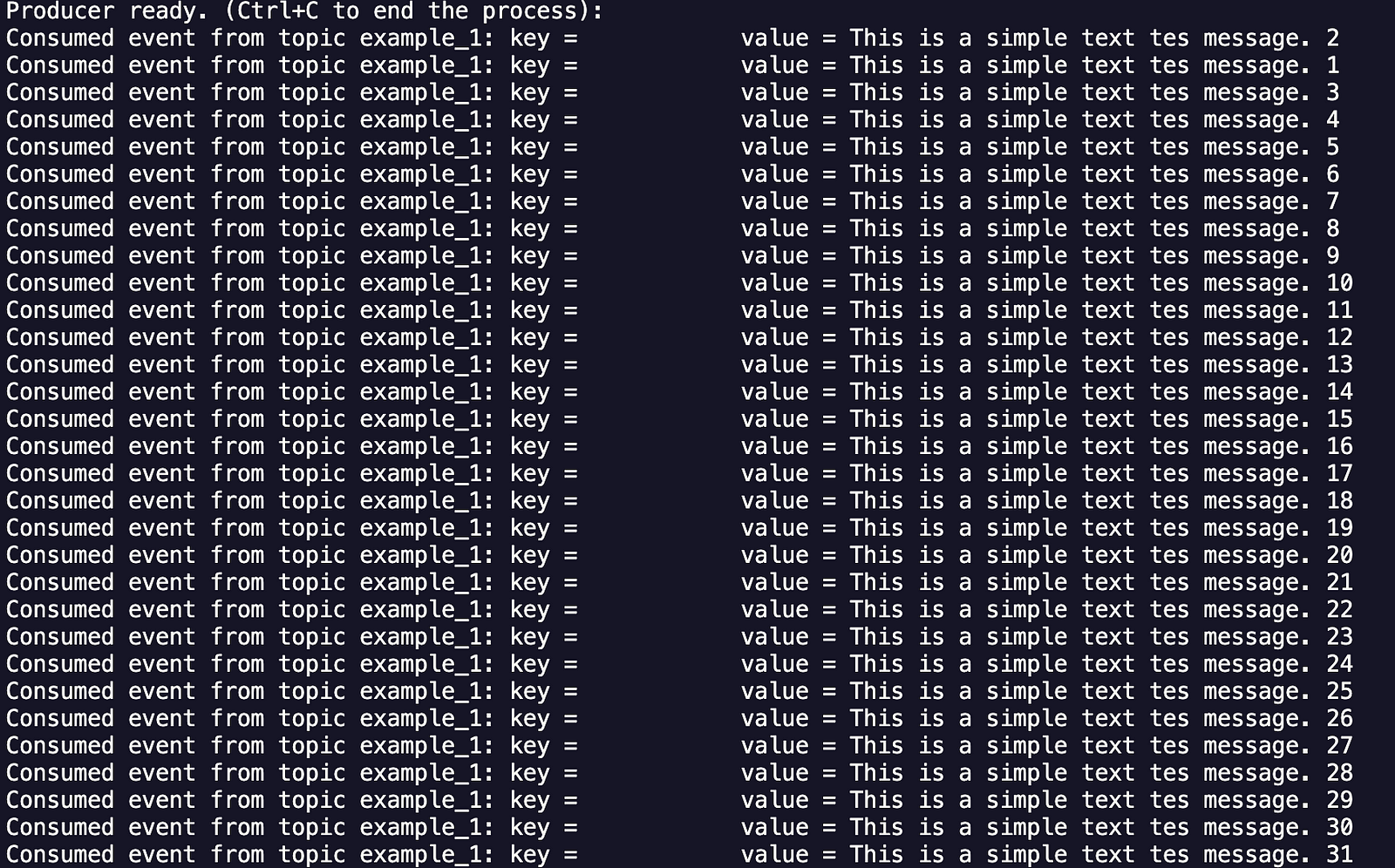
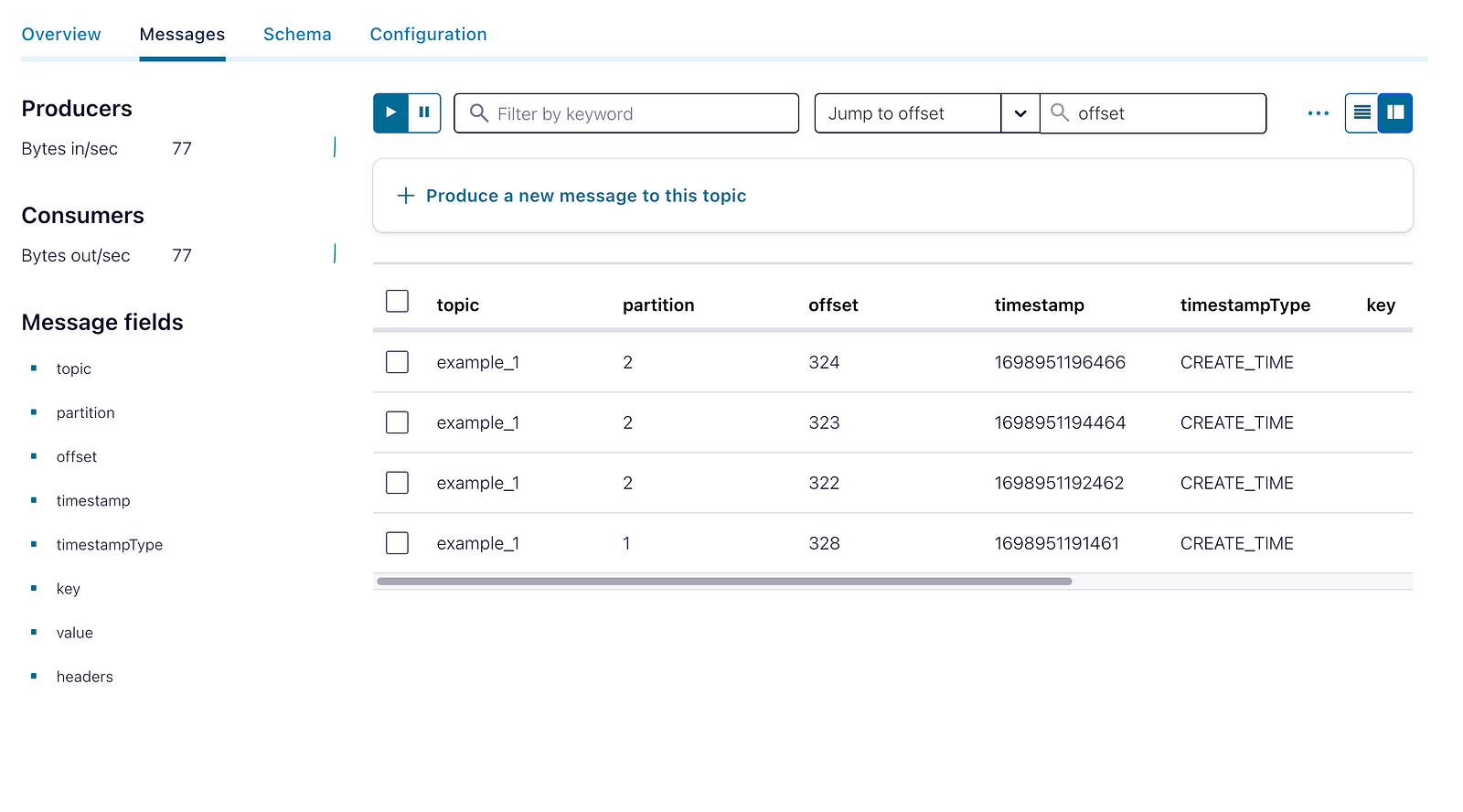
Conclusion
Confluent Kafka is more than just Apache Kafka; it’s a comprehensive event-streaming platform that extends the capabilities of Kafka to support enterprise-grade use cases. With features like schema management, connectors, and stream processing capabilities, Confluent Kafka has become a go-to solution for organizations looking to harness the power of real-time data and event-driven architectures. Its rich ecosystem, security features, and professional support make it a compelling choice for modern data-driven applications.